这里的服务器模型指的是服务器的并发模型,即多客户端连接服务器时,服务器的对客户端连接的处理策略。
1. 单线程阻塞模型
一般大家写socket客户端、服务端测试的时候,都是在服务端监听端口后,当客户端连接之后,服务端接收连接之后便进入等待客户端消息,客户端发一条数据,服务端对应处理一条数据。也就是下图所示:
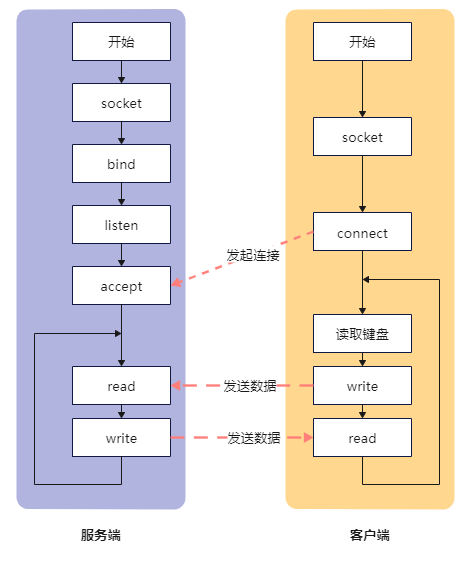
服务端在启动之后阻塞在accept等待客户端连接,待客户端连接成功之后便阻塞在read处等待客户端发送数据。
同样,一般我们会在客户端启动之后,阻塞在键盘读取,等我们输入一些字符后,客户端便将这些数据发送给客户端。紧接着客户端便阻塞在read处等待服务端的数据返回。
这里我们出现很最多的是阻塞。这也导致了这个服务端在与一个客户端进行通信时,并不能在处理第二个客户端的请求。
当然这种处理模型一般也只出现在学习socket通信的样例场景之下。
2. 多线程/多进程阻塞模型
对于多线程/多进程模型实际环境中用的并不是很多,记得当时上课的时候老师教着写了下。
这个模型的主要精髓在于当服务端接收完客户端的连接之后,启动新的线程或进程去处理客户端后续的数据交互,这样即使阻塞在读取客户端数据,也不至于将整个服务端给阻塞住,影响服务端后续其他客户端的处理。
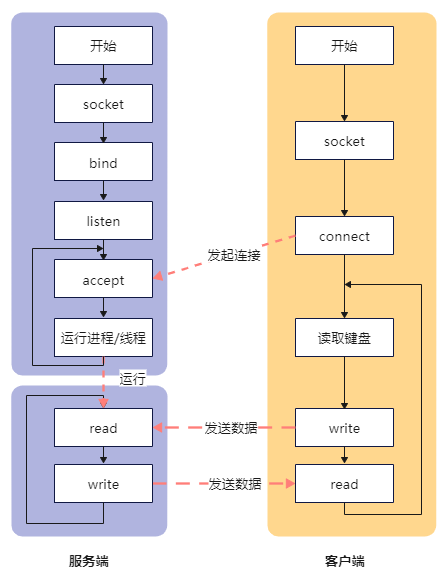
由于每个连接的处理都需要新建线程/进程,将会消耗很大的资源。
3. 单线程多路I/O复用模型
多路I/O复用技术在网络编程里指的是单个线程/进程同时监测多个文件描述符是否具有I/O的能力,一旦其中有某些描述符具备可读、可写的能力时,系统就能够通知应用去处理,当没有相关的事件时,所处任务将让出cpu。多路复用这个概念源自通信技术,也就是在把多个来源信号通过复用器(比如时分复用)在一个信道上传输,接收端再通过复用器将多路信号分解出来。
Unix网络编程中常用的多路I/O复用接口有select、poll和epoll,就目前而言用的最多的是epoll,而为什么很少使用前两者可以参见I/O多路复用(三)epoll总结。
服务端在使用epoll后,可以将多个监听的文件描述符(比如服务端的监听描述符、客户端的连接描述符)都加入epoll中,由epoll来提供统一的事件通知。这样单个线程就可以处理多个客户端的请求,大大地提升单线程的处理吞吐量。
所以在实际编程中,我们首先将服务端的监听fd通过epoll加入到事件监听中,当epoll通知该fd可读时,一般为有客户端连接连接监听的地址上,我们此时通过accept函数接受连接,并将返回的连接的fd再次加入到epoll中,后续对于此连接的可读、可写都将由epoll来进行事件通知。通过这种方式达到一个线程监听多路I/O的目的。但需要注意的是,加入到epoll监听中的描述符应是非阻塞的。
在这种场景下,服务端与客户端的交互流程如下图所示。
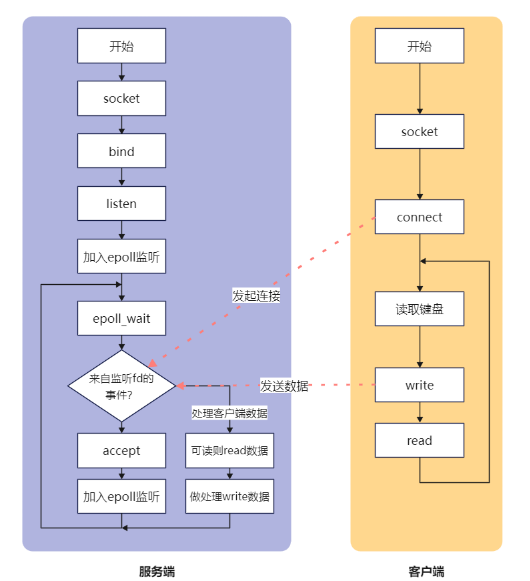
使用多路I/O监听将会在一个线程中处理处理来自多个连接的建连、读、写事件,大大提高利用能力。
4. 多线程多路I/O复用模型
多线程的多路I/O复用与单线程的类似,区别在于每个线程都启动epoll监听线程,而每个线程的epoll都处理服务端的监听fd。这样当客户端进行连接时,将会将由其中的一个线程的epoll进行处理,使用多线程可以避免当某一个连接处理时间过长,导致所处的线程阻塞,其他连接得不到处理的情况。
5. 多进程多路I/O复用模型
这种模型典型的使用者是Nginx。所有的工作进程都监听同个服务端端口(通过地址、端口复用,以及fork来实现)。
但是其中也会存在所谓的“惊群问题”,即既然是多个进程监听着一个端口,当有连接过来时,所有的进程都会去响应这个连接事件,所有人都会尝试去accept这个连接,可实际上只有其中一个进程可以成功accept,而其他进程则无功而返,造成从阻塞中无用的唤醒、资源的无谓消耗。
而ngnix为解决这个问题,使用锁的机制来解决这个问题,即所有进程都会在被唤醒的时候获取共同的一把文件锁,只有拿到这把锁的人才可继续进行accept,拿不到的人则继续等待。
6. 总结
至此,已经将常见的服务端的并发处理模型介绍完毕。其中比较常用的是单线程多路I/O复用、多线程I/O复用。
后续的课程中,我们将使用单线程多路I/O复用模型来编写我们的HTTP服务器。